AI Safety Summary (Q1 2023 Cohort)
| 4766 words- Background, Context, & Goals 📚
- Week 0 (Optional): Introduction to ML
- Week 1: Artificial General Intelligence 🤖
- Week 2: Reward misspecification and instrumental convergence 🏅
- Week 3: Goal misgeneralization 🥅
- Week 4: Task decomposition for scalable oversight 👀
- Week 5: Adversarial techniques for scalable oversight 👾
- Week 6: Interpretability 🔍
- Week 7: Agent Foundations & Governance 🏛️
- Footnotes 🦿
- Links to Materials [~7 hours] 🔗
- Materials for Week 0: Introduction to ML [~165 minutes]
- Materials for Week 1: Artificial General Intelligence [~95 minutes]
- Materials for Week 2: Reward misspecification and instrumental convergence [~80 minutes]
- Materials for Week 3: Goal misgeneralization [~95 minutes]
- Materials for Week 4: Task decomposition for scalable oversight [~110 minutes]
- Materials for Week 5: Adversarial techniques for scalable oversight [~90 minutes]
- Materials for Week 6: Interpretability [~100 minutes]
- Materials for Week 7 - Default: Governance [~80 minutes]
- Materials for Week 7 - Alternative: Agent Foundations [~100 minutes]
Background, Context, & Goals 📚
This is my summary & extrapolations for the Artificial Intelligence Technical Safety Fundamentals Alignment Course (“Course” hereafter) offered by BlueDot, which spun out of Effective Altruism Cambridge in collaboration with Richard Ngo from OpenAI/DeepMind. In total, the Course is expected to take ~30 hours taking place over 8 weeks with pre-readings & discussions and includes a self-guided project.
Although I have ~1000s hours of AI/ML training, the Course begins with an optional Week 0 that takes ~2 hours to get up to speed conceptually. I will assume this (admittedly small) audience has this level of familiarity and that these summaries gloss over those preliminary details. Instead, the focus will be the core 8 weeks of content with the occasional detour into “what it’s like inside my mind.” Lastly, my involvement with the Course began in 2021 where I started as a participant led by Michael Chen. In both 2022 & 2023, I was offered to be a paid facilitator for 1 cohort each iteration.
Instrumental Goals
My instrumental goals for facilitating the Course & independently writing these summaries are to:
- Distill ~30 hours of readings & discussions into ~30 minutes of reading here.
- 30 minute estimate = ~6k words at 200 WPM
- Improve, clarify, & solidify my own understanding around this challenging topic while also staying up to date on the latest research.
- Practice my communication skills for AI safety information and to “find ways to help people understand the core parts of the challenges we might face, in as much detail as is feasible.” [Cold Takes]
- Establish connections with those also interested in working in AI safety.
- Connections (Direct work): Either these folks will be future colleagues or will have overlap in the field of AI safety. In my view, I believe most industries will be impacted by the advancements of AI.
- Connections (Indirect work): As most participants are technical, I can see a future where SWE/researchers are working for any of the MAMAA companies and could be part of the capabilities frontier. I believe that capabilities SWE/researchers should be knowledgeable about AI safety.
- [Bonus] Establish myself as a credible & properly nuanced source of AI safety knowledge.
- [Bonus] By staying up-to-date on the latest research, directly contribute to the advancement of “helpful, honest, and harmless” AI systems with a focus on strategy.
My final goals are here. Lastly, I would like to thank Greg Tracy & my cat Bunny for feedback where all the mistakes are my own or Bunny’s suggestions from walking on the keyboard.🐈
{kind=link}
Week 0 (Optional): Introduction to ML
High level, machine learning (a subset of artificial intelligence) is giving a machine a method to which it may learn from data. The current paradigm leverages mostly deep learning where the system is often shown millions of examples to generalize to a sample of never-before-seen information (via a train-dev-test split process). In my view, generalization is among the most interesting aspects of ML as it is so difficult to do well. Humans are given a few examples and generalize rather easily. As of right now, AIs struggle to generalize (more in my Week 1 summary below).
Given that most of the latest research deploys deep learning, Ngo’s diagram outlines Optimization techniques and Neural network architectures where the ~2 hours of videos cover both of these deep learning concepts in detail. The most salient of these is the transformer as it has been demonstrated to learn context and be deployed in various use cases (such as text and images).
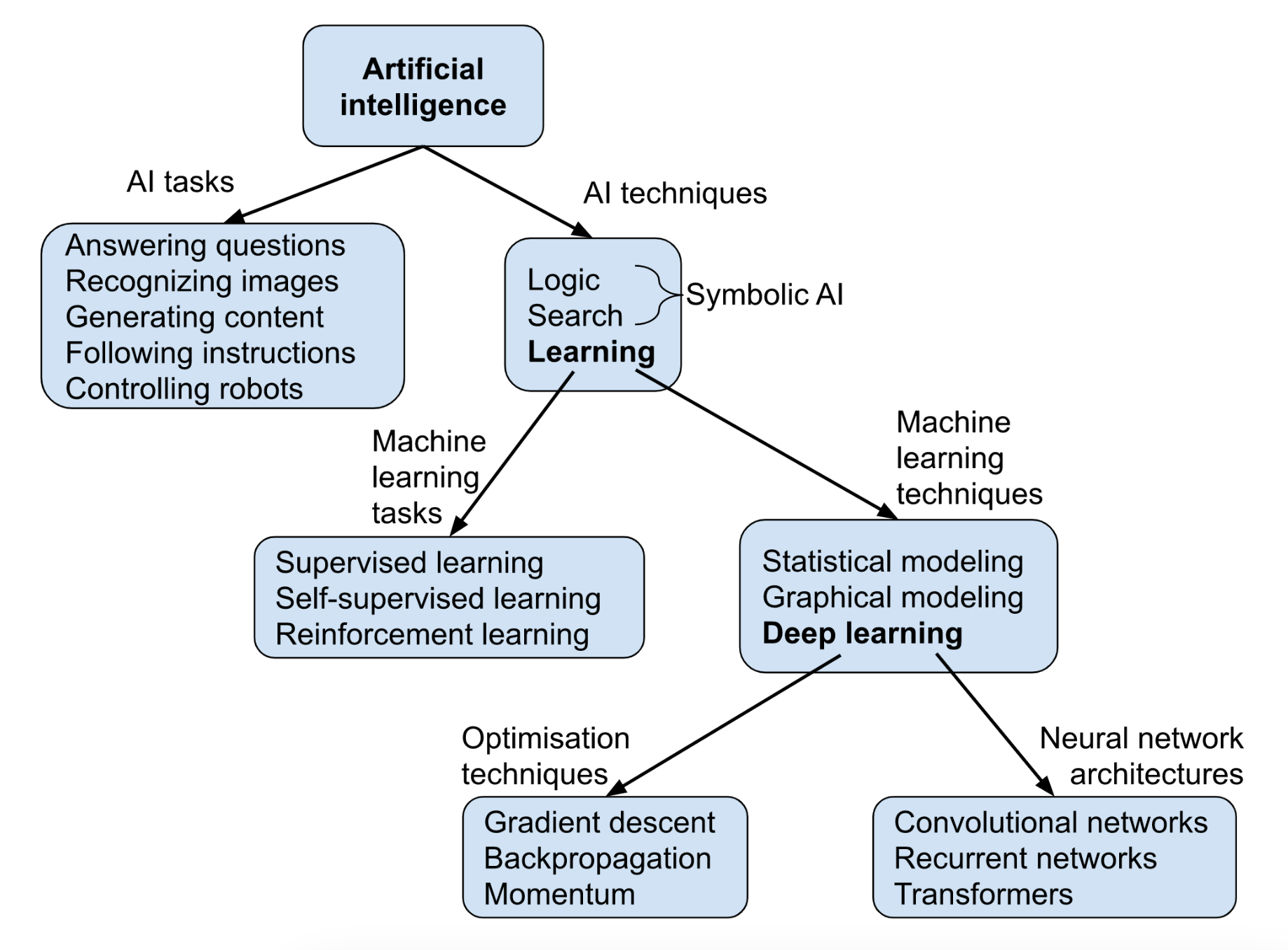
Diagram by Richard Ngo (2021)
Finally, Ngo breaks down ML tasks further toward the end of his post.
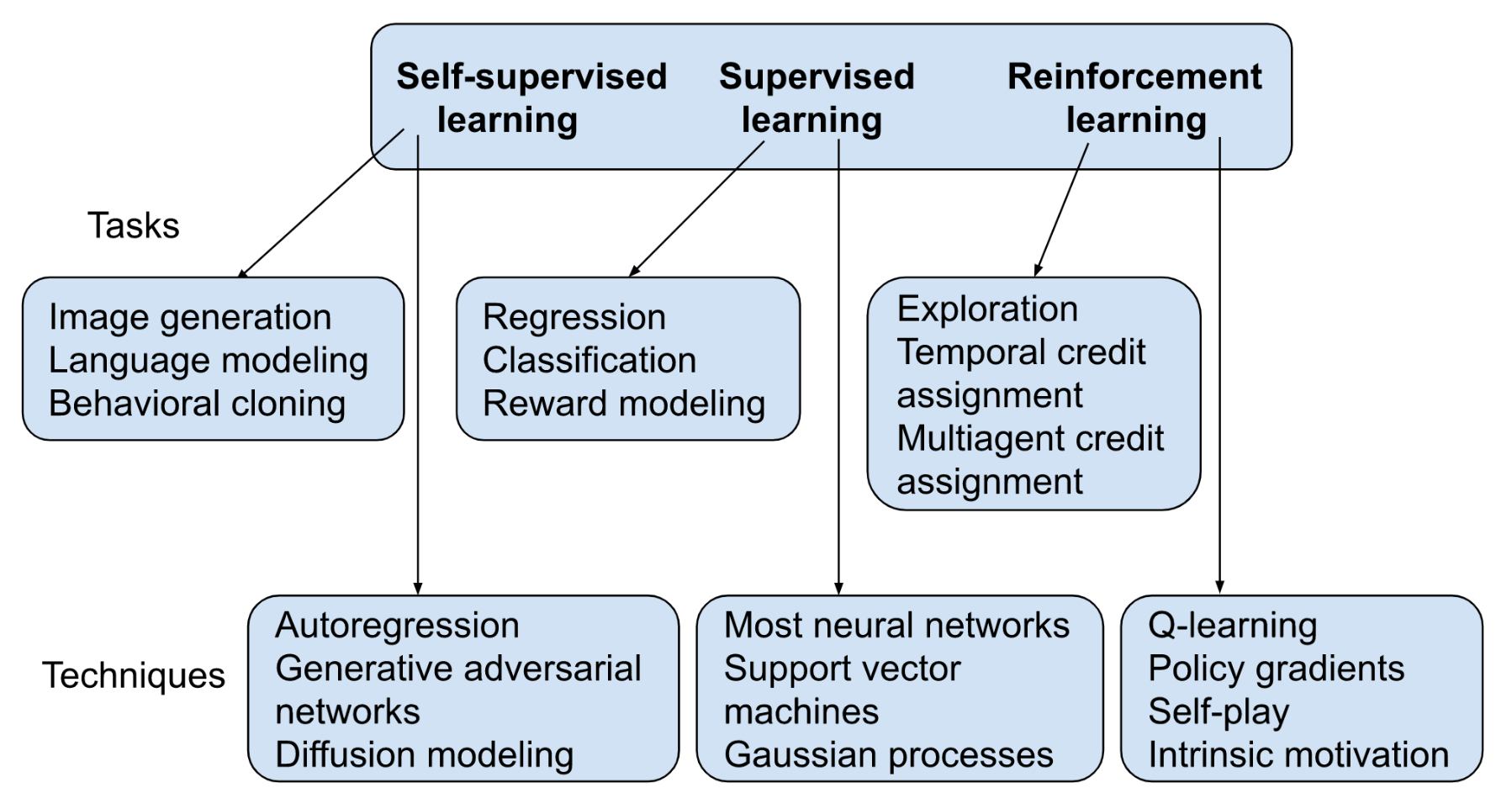
Diagram by Richard Ngo (2021)
Week 1: Artificial General Intelligence 🤖
Intelligence
The Course first better defines intelligence and, in particular, Artificial General Intelligence [AGI]. “Intelligence measures an agent’s ability to achieve goals in a wide range of environments.” [Legg & Hutter (2007)] Legg & Hutter define intelligence mathematically in their paper but the vague intuition works well for the Course. Steve Wozniak has the clever/cute Coffee Test to determine whether a system possesses general intelligence.
A machine is required to enter an average American home and figure out how to make coffee: find the coffee machine, find the coffee, add water, find a mug, and brew the coffee by pushing the proper buttons.
Although the Course doesn’t officially cover the various types of intelligent agents, I’d like to do so below for the most popular kinds:
- Transformative AI [TAI]: An AI that brings about a dramatically different future (roughly comparable but probably more significant than the agricultural or industrial revolution). [OpenPhil]
- Artificial General Intelligence [AGI]: An AI that’s broadly capable of most/all functions that an animal (traditionally a human) can do. We are still within the scale of what we can comprehend as intellectuals have created a rough intuitive scale of ants, bees, crows, & humans. We’re quickly scaling up the ladder as artificial minds become more and more capable - see Galaxy timelines chart where mouse-brain-sized model is projected for 2023.
- Fun fact: Orangutans, pigs, and octopi are among the smartest, less well-known animals (most think of chimps, dolphins, or mice first with a longer list here)
- Seed AI: An AGI that recursively rewrites its own source code without human intervention. [Yudkowsky (2007)]
- Superintelligent AI: An agent that far surpasses the brightest human minds both individually and even what can be done collectively. If the Manhattan Project was the combination of the brightest minds, a superintelligent agent would view them as intellectually equal as we view ants (but probably even more inferior in this axis if my anthropological lens is true in the first place).
- In my view, an AGI will very likely become a superintelligent agent. We’d need to bound the AGI or rethink how we design AI systems. Bostrom explores several boxing methods in his book that aren’t all that promising and suggests of coming up with novel ways to ensure that a Seed AI has certain values “pre-loaded.”
Timelines
Although AIs struggle right now with generalizing, I believe our uniqueness & intellectual superiority will largely fade by the end of this century. This forecast of “TAI is ~80% likely by the end of this century” (paraphrasing) comes mainly from the 2020 Bio-anchors paper by Ajeya Cotra. Holden Karnofsky later summarizes where the “Experts” stood in 2021, and he concludes a ~2/3 chance by the end of this century. Cotra later updated her forecast in 2022 with the median likelihood to be ~2040 now vs. ~2050 previously. By induction, I can assume that she also increased her ~80% forecast of TAI by the end of this century as well. It is worth noting that these forecasts are to bound our expectations vs. seeing them as precise figures. Metaculus has its median forecast for AGI around 2035 during this writing.
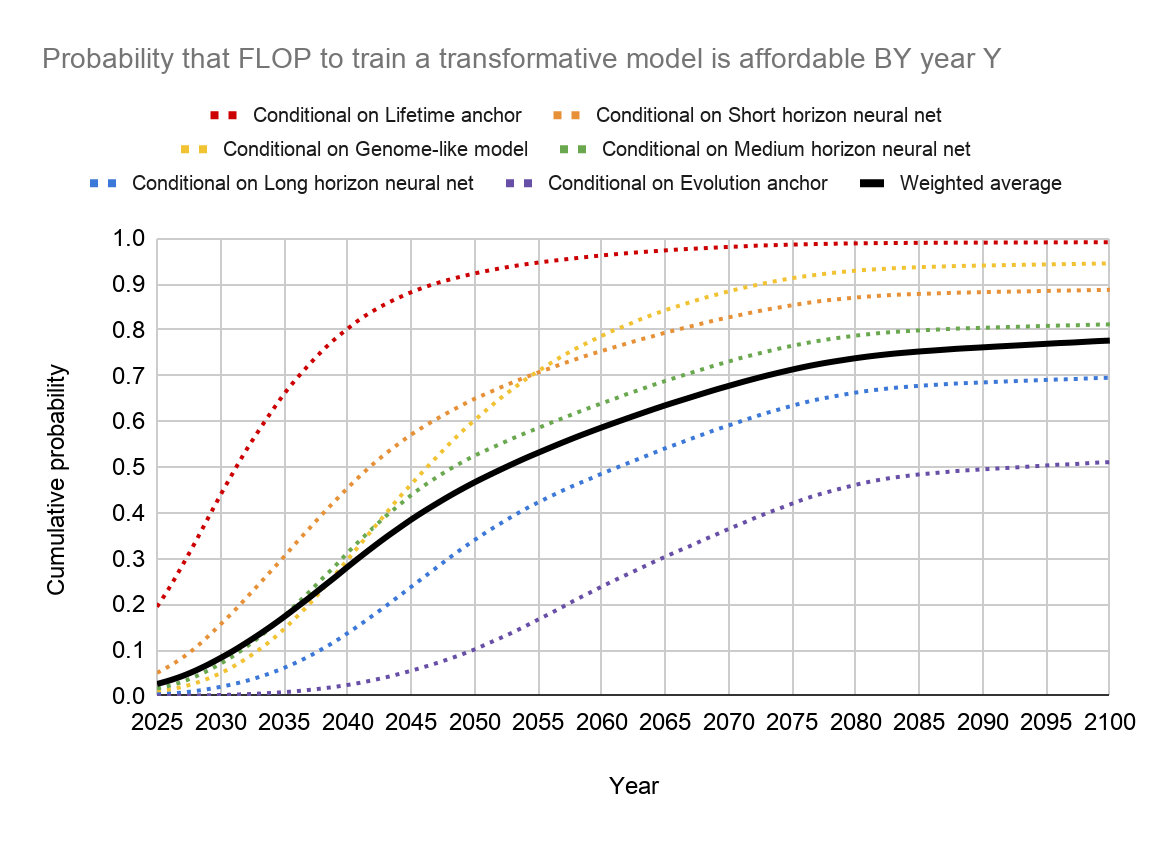
Chart from Bio-Anchors by Cotra from Cold Takes
Given these timelines, I hope (and with modest confidence believe) we’re in the slow takeoff scenario where we’ll see continuous acceleration of technological progress. Practically speaking, I don’t think there’s much value in considering a fast takeoff scenario as we’d be unable to react to a superintelligent agent.
The bulleted list of the types of intelligence has a feeling of increasing levels of complexity or impressiveness. A lighter version is explored in several candid/hopeful short stories in AI 2041 by Kai-Fu Lee. He describes realistic AI, or “technologies that either already exist or can be reasonably expected to mature within the next twenty years.” Lee & other leaders in AI plausibly seem skeptical of TAI happening this century. I think the best resource pushing back on this view is from All Possible Views About Humanity’s Future Are Wild by Holden Karnofsky. In this post Karnofsky explores this “conservative view” by steelmanning various timelines of 100 years to 100,000 years. For galaxy-scale timelines this range would converge on the same pixel in the visual below. Granted the level of urgency would (thankfully) lift from our collective ~10 billion shoulders alive this century. However, we’d still be among a tiny group of people placed in an important time period. With 125 quadrillion (1015) possible future persons on Earth, we’re in the first ~100 billion people so far (or among the first 0.0001% people to ever exist on this planet). In other posts Karnofsky expands on the challenges within AI safety & that many problems remain unsolved. The rest of the Course focuses on the various problems & issues that emerge. 1
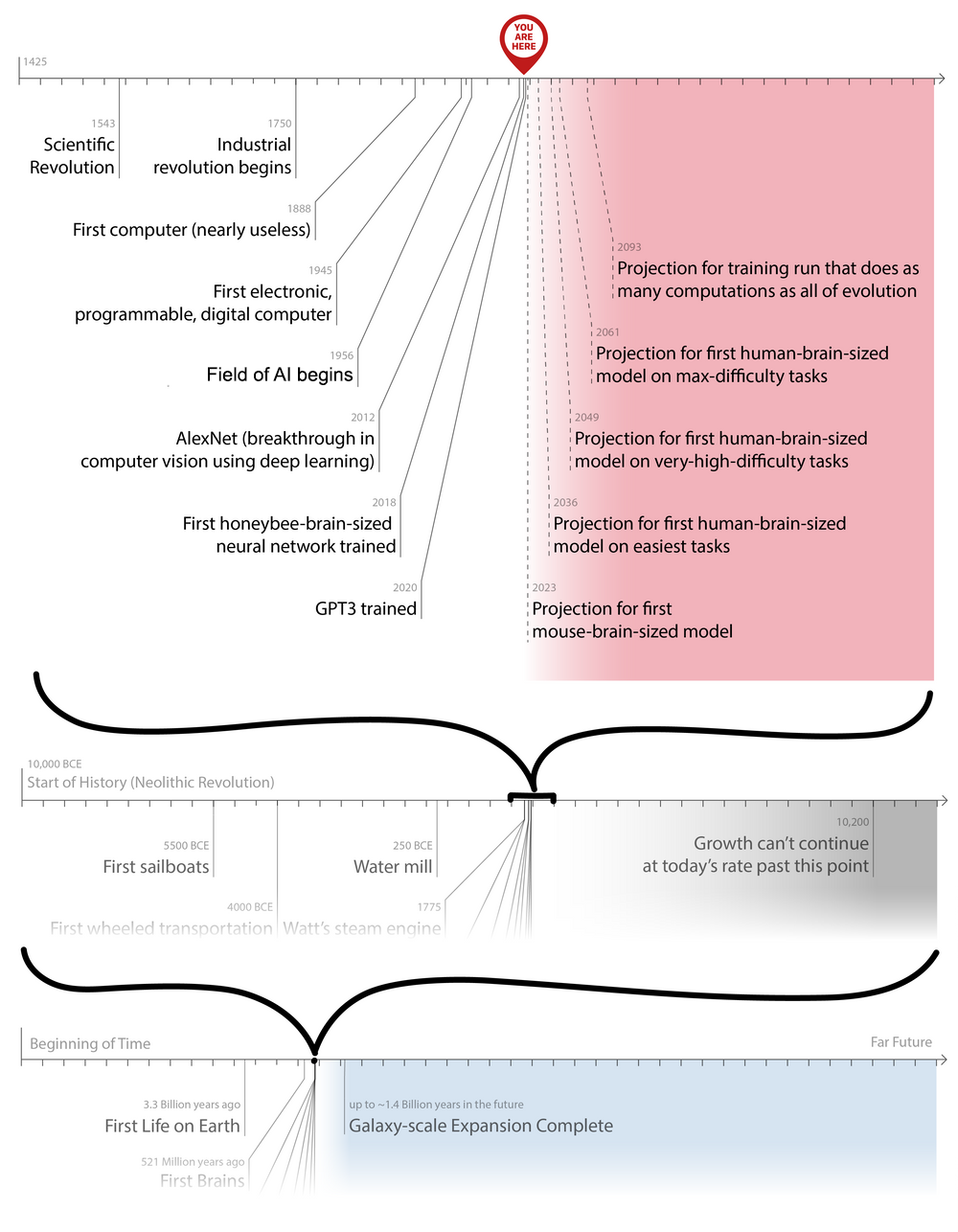
Additionally, I will outline another approach to understanding AI timelines and the main players in the space. EFF used to track various narrow AI/ML metrics with the last entries from Feb-2019, ending with GPT2. The main story then (and still today) is that progress is happening rapidly. Riedel & Deibel put together a bibliographic database for the 16 major institutions (excluding academia) tracking the output of AI safety papers. Relatedly, ~25% of deep learning papers come from the Fortune Global 500 (Tech) companies.
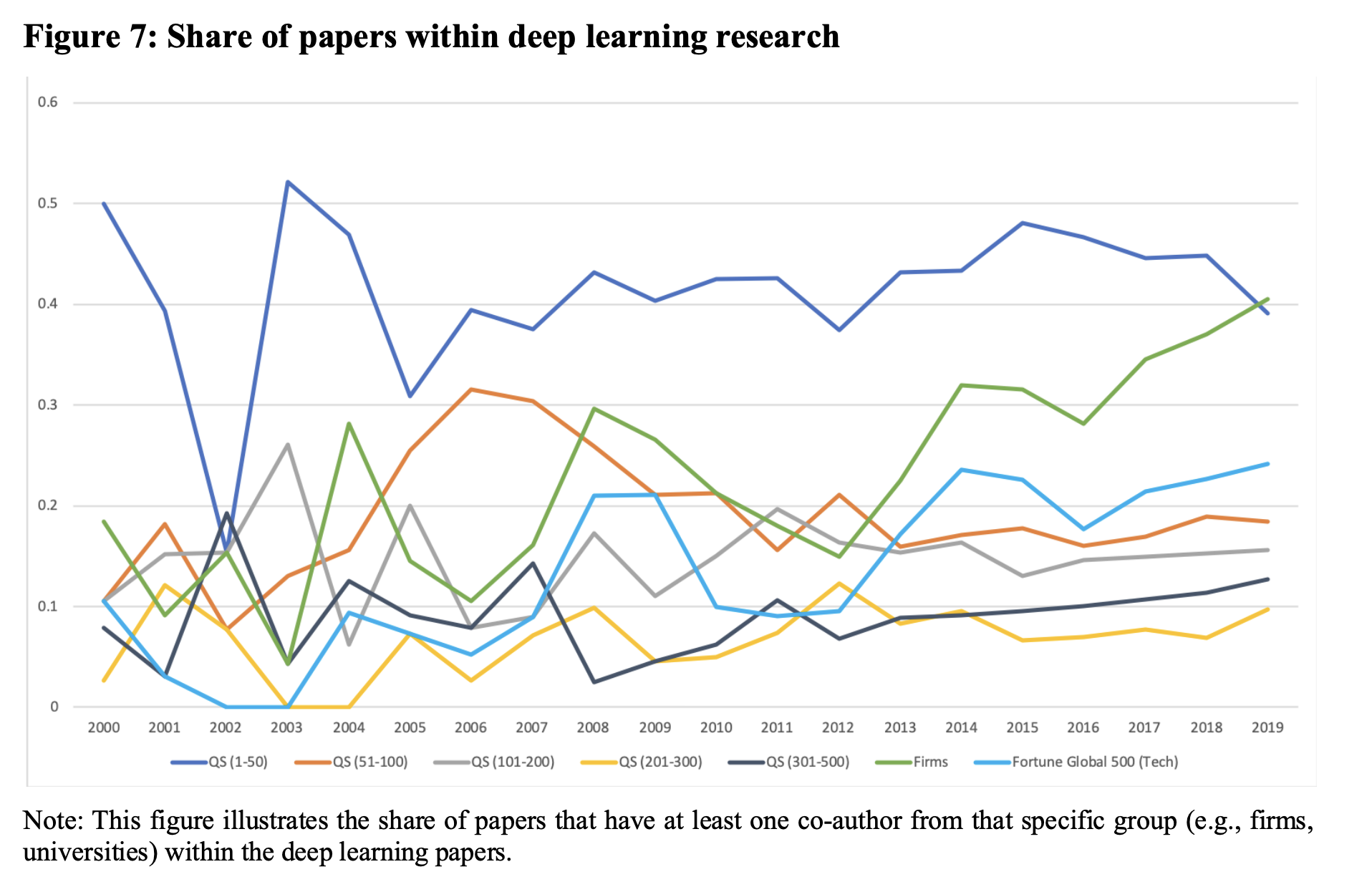
And ~40% of deep learning research comes from the Top 50 Universities. This is consistent with Tim Dettmers’ broad statement about research in his blog post: “0.0006% of people publish 41% of papers in research journals.” I’m noting the inequalities in research as I imagine these will maintain for the foreseeable future. Week 7 might cover this trade-off between “small research community collaborating efficiently prone to ivory tower type biases” and “large research community slowly integrating various perspectives.”
The Course defines the recently created term “foundation models.” A foundation model is a model trained on broad data that can be fine-tuned to a range of more specific tasks. The scale & scope of foundation models are what makes it unique. AI progress traditionally has 3 inputs: software, hardware, and data. To me, the term foundation model is emphasizing the leveraging of Moore’s Law (hardware acceleration via improved computation costs) that’s able to intake mountains of data (Sutton’s scaling law) in larger, generalized methods via transformers (new software from a 2017 paper). Bringing this all together, it seems like foundation models might be the catalyst in which we see TAI.
Week 2: Reward misspecification and instrumental convergence 🏅
We refined our formal definition of intelligence & have some high-level intuition of progress & capabilities for AI. Why put safety into “AGI Safety” at all? This how I was introduced to the Alignment Problem:
- Orthogonality Thesis: Intelligence and final goals can be two different axes within an AGI. Therefore, the space of possibilities includes “Superintelligence, Misaligned with Human Goals.” [Bostrom]
- An AGI being misaligned to human values seems more likely than to be aligned. This is because by-and-large the AGI will seek power (almost always an instrumental goal) to accomplish its terminal or final goal. [Omohundro]
- Even if the above two are solved, it is still possible for an AGI to create a terrible outcome that results from the value loading problem.
- Using the example goal of “cure cancer” to an AGI: the AGI could solve for this by giving everyone a pill where they die at the age of 40. The AGI found that cancer is much more common in old age and solved the goal given but is not aligned with human values.
From my “Why AGI?” post
MIRI also has these points and more in their major concerns for alignment.
The Course begins to break down these “what could go wrong” theses focusing first on reward misspecification. Reward misspecifications occur because real-world tasks have numerous, often conflicting desiderata. Reward hacking (a subset of reward misspecification) is where RL agents exploit gaps in misspecified reward functions. [Pan (2022)] The other type of reward misspecification is from humans not designing the correct reward function in the first place (e.g. CoastRunners example). Specification gaming is a behavior that satisfies the literal specification of an objective without achieving the intended outcome. [Deepmind (2020)] Point 3 above is one hypothetical example of many.2
Instead of explicitly outlining our criteria directly into a reward function, researchers have implemented a couple methods of allowing an AI to learn from humans.
- Reinforcement Learning from Human Feedback [RLHF]: A “human in the loop” process where a human judge ranks two outputs with one being better than the other. Then, feed that information back into the model and iterate.
- Inverse Reinforcement Learning: Allows the reward function to be learned (or create a black-box model of the reward function) purely from observations.
If you’re not convinced & short on time, I think the most accessible resource for the AGI alignment problem is in What failure looks like by Paul Christiano, which I think could make for an interesting novel.
Is it an AI Catastrophe for AGI to give us the entire Milky Way but take over the rest of the universe? Upon first glance, it seems like missing out on our cosmic endowment isn’t ideal, but it’s better than going extinct.
Week 3: Goal misgeneralization 🥅
- Goal misgeneralization: An instance of misgeneralisation in which a system’s capabilities generalise but its goal does not generalise as desired. Deepmind (2022)3
- Situational awareness: At some point, an AI agent becomes knowledgeable enough to understand that it’s a deep learning model being trained to accomplish some goal. This kind of knowledge “is likely helpful for getting good performance on complex real-world tasks.” [Cotra (2021)]
- Outer alignment: The human takes their meta-objective and codes this into the base objective function with an AI agent.
- Inner alignment: Further inside the AI agent, the system has a mesa-objective encoded via its deep learning architecture.
- Evolution Analogy: Evolution’s goal is for us to produce as many offspring as possible. This is the base objective. Yet, humans puruse many goals that may or may not relate to Evolution’s goals (say being happy for its own sake). We may have inner alignment with evolution. Yet, it’s possible to be inner misaligned by being childfree. Evolution did its outer alignment job and created a person.
- It’s also possible for evolution to have outer misalignment in the case of dodo bird where it was able to produce offspring yet winning the (possibly the first?) Darwin Award as it was unfit for survival when sailors brought them to extinction.
Another problem that emerges within this category is being deceptively aligned. While I generally try to avoid anthropomorphising AI, it is easier to imagine an AI that behaves well during training while knowing it is in training. Then once deployed, it will pursue its real goals. Ideally, we want to avoid this kind of misalignment, and this remains an active realm of research. Cotra creates an analogy where you’ve inherited a substantial amount of wealth as an 8-year-old (strikingly similar to Harry Potter) yet without a trusted adult. Therefore, the goal is then to set up a process/test to find the “Saints” knowing the other two types exist. Cotra outlines 3 types of models/agents we’re likely to encounter using the deep learning paradigm.
- Saints: genuinely want to help you.
- Sycophants: want your approval, regardless of long-term consequences
- Schemers: want your wealth to pursue their own agendas.
We have already seen simpler forms of deception. In this example, the goal was for the digital robot arm to grab the ball. Yet, it found the greedy solution was to place itself between the ball and camera making it appear as if it accomplished the goal. While this is a toy example with a concrete goal, how would we go about solving real-world problems that have fuzzy goals?
Week 4: Task decomposition for scalable oversight 👀
Key Terms:
- Scalable Oversight: The ability to provide reliable supervision (in the form of labels, reward signals, or critiques) to models in a way that will remain effective past the point that models start to achieve broadly human-level performance.
- Task decomposition: A planning method that involves breaking down a larger task into smaller, more manageable sub-tasks. This creates a hierarchical model of the root task, which can be dealt with at the lowest possible level.
- Iterated amplification: An approach to AI alignment, led by Paul Christiano. Initially build weak aligned AIs then recursively use each new AI to build a slightly smarter & still aligned AI.
ChatGPT
Introduction Training AI models to perform complex tasks remains a formidable challenge. Researchers are continuously exploring new methods to improve the training and performance of AI systems, particularly in areas that are difficult or time-consuming for humans to evaluate. This blog post synthesizes key findings from five recent papers that tackle various aspects of this challenge, from scalable oversight to novel prompting strategies.
Scalable Oversight in AI Systems The first paper delves into the concept of “scalable oversight,” which is crucial for developing safe, general-purpose AI systems. The paper proposes an experimental design that focuses on tasks where human specialists excel but where both unaided humans and current AI systems fall short. A proof-of-concept experiment demonstrated that humans interacting with an unreliable large-language-model dialog assistant outperformed both the model alone and their unaided selves. This is a promising sign that scalable oversight is feasible to study with current models and that large language models can assist humans in complex tasks.
The Iterated Amplification Strategy Two papers discuss a training strategy called “Iterated Amplification.” This approach aims to build a training signal for complex problems by solving easier subproblems. Unlike Expert Iteration, another training strategy, Iterated Amplification does not rely on an external reward function. The results in algorithmic environments indicate that this method can efficiently learn complex behaviors. This strategy could be particularly useful for real-world learning tasks with complex objectives that are hard to specify.
Abstractive Summarization of Fiction Novels The fourth paper focuses on the task of abstractive summarization of entire fiction novels—a task that is both hard and time-consuming for humans to evaluate. The method combines human feedback with recursive task decomposition. The GPT-3 model was fine-tuned to perform recursive summarization. During inference, the model first summarizes small sections of the book and then recursively summarizes these to produce a final summary. The model achieved state-of-the-art results on the BookSum dataset and performed competitively in the NarrativeQA benchmark. This approach allows human labelers to supervise and evaluate the model quickly, even without reading the entire books.
Improving Reasoning Abilities: Chain of Thought Prompting The fifth paper explores how to improve the reasoning abilities of large language models, particularly in multi-step reasoning tasks. It introduces a method called “chain of thought prompting,” which enables models to decompose multi-step problems into intermediate steps. This method allows large language models to solve complex reasoning tasks that are not achievable with standard prompting techniques.
Least-to-Most Prompting: A Novel Strategy The final paper addresses the limitations of chain-of-thought prompting, particularly when solving problems that are more complex than the demonstration examples. It introduces a new strategy called “least-to-most prompting,” which is implemented in two stages. First, it breaks down a complex problem into subproblems. Then, it solves these subproblems sequentially, with each subproblem aided by the solutions to previous ones. This method significantly outperformed chain-of-thought prompting. For instance, the GPT-3 code-davinci-002 model using least-to-most prompting achieved a 99.7% accuracy on the SCAN benchmark with just 14 examples, compared to 16.2% accuracy by chain-of-thought prompting.
Conclusion The landscape of AI training strategies is complex and ever-evolving. Researchers are making progress on multiple fronts, from developing methods for scalable oversight to devising new prompting strategies that improve the reasoning abilities of large language models. These advancements are not only academic exercises but are crucial steps toward creating AI systems that can assist humans in increasingly complex tasks. As AI continues to integrate into various aspects of our lives, understanding and implementing these advanced training strategies will be key to ensuring that these systems are both effective and safe.
Week 5: Adversarial techniques for scalable oversight 👾
Week 6: Interpretability 🔍
Week 7: Agent Foundations & Governance 🏛️
My cohort chose Agent Foundations while I preferred the default choice of Governance/Strategy.
Agent Foundations
Governance
- When AGI is a ‘Manhattan Project’ away
- Anthropics LLM Surprise
- Holden’s AI Strategy set of questions
- Stanford AI Index
- Why TAI is hard
- Why AI will Save The World
- Compute Monitoring
Footnotes 🦿
- I’m borrowing the mathematical definition of “problem” where a solution may exist. [Wikipedia] Some problems don’t have a solution (e.g. free will, absolute moral truths etc.). I think what is usually meant is “issue” where there is an existing solution, whether it’s known or unknown.
- The researchers at Deepmind made a combined list of specification gaming examples from AI research if that’s of interest.
- The researchers at Deepmind made a different combined list of goal misgeneralization examples from AI research if that’s of interest.
Links to Materials [~7 hours] 🔗
I made a Spotify Playlist for the 2022 iteration of the Course with some of the readings that should be viewed as supplemental and not as a substitution. Lastly, I add in optional readings that I personally view as important enough to be included here & would recommend.
Materials for Week 0: Introduction to ML [~165 minutes]
Readings
- A short introduction to machine learning by Richard Ngo (2021)
- Machine Learning for Humans (2017) by Vishi Maini and Sabri
Videos
- But what is a neural network (2017)
- Gradient descent, how neural networks learn (2017)
- What is backpropagation really doing? (2021)
- What is self-supervised learning? (2021)
- Introduction to reinforcement learning (2021)
- Transformers, explained: Understand the model behind GPT, BERT, and T5 (2021)
Materials for Week 1: Artificial General Intelligence [~95 minutes]
- Visualizing the deep learning revolution (2023) by Richard Ngo
- On the opportunities and risks of foundation models (2022) by Bommasani et alia
- Four Background Claims (2015) by Nate Soares
- AGI safety from first principles (2020) by Richard Ngo
- [Video] Why and how of scaling large language models (2022) by Nicholas Joseph
- Biological Anchors: A Trick That Might Or Might Not Work (2022) by Scott Alexander
- Intelligence explosion: evidence and import (2012) by Luke Muehlhauser and Anna Salamon
- [Advanced ML] Future ML Systems Will Be Qualitatively Different (2022) by Jacob Steinhardt
- [Advanced ML] More Is Different for AI (2022) by Jacob Steinhardt
- [Optional] The Bitter Lesson (2019) by Rich Sutton
- [Optional] AI and Efficiency (2020) by Danny Hernandez and Tom Brown
- [Optional] AI and Compute (2022) by Andrew Lohn and Micah Musser
Materials for Week 2: Reward misspecification and instrumental convergence [~80 minutes]
- Specification gaming: the flip side of AI ingenuity (2020) by Victoria Krakovna et alia
- Learning from Human Preferences (2017) by Paul Christiano, Alex Ray and Dario Amodei
- Learning to Summarize with Human Feedback (2020) by Jeffrey Wu et alia
- The alignment problem from a deep learning perspective (2022) by Richard Ngo et alia
- Superintelligence: Instrumental convergence (2014) by Nick Bostrom
- [Video] Inverse reinforcement learning example (2016)
- The easy goal inference problem is still hard (2018) by Paul Christiano
- [Advanced ML] Optimal Policies Tend To Seek Power (2021) by Alex Turner et alia
Materials for Week 3: Goal misgeneralization [~95 minutes]
- Goal misgeneralization: why correct specifications aren’t enough for correct goals (2022) by Rohin Shah et alia
- [Video] The other alignment problem: mesa-optimisers and inner alignment (2021)
- Why alignment could be hard with modern deep learning (2021) by Ajeya Cotra
- What failure looks like (2019) by Paul Christiano
- [Advanced ML] Thought Experiments Provide a Third Anchor (2022) by Jacob Steinhardt
- [Advanced ML] ML Systems Will Have Weird Failure Modes (2022) by Jacob Steinhardt
- [Advanced ML]The alignment problem from a deep learning perspective (2022) by Richard Ngo et alia
Materials for Week 4: Task decomposition for scalable oversight [~110 minutes]
- [Video] AI Alignment Landscape (2020) by Paul Christiano
- Measuring Progress on Scalable Oversight for Large Language Models (2022) by Samuel Bowman
- Learning Complex Goals with Iterated Amplification (2018) by Paul Christiano and Dario Amodei
- Supervising strong learners by amplifying weak experts (2018) by Paul Christiano, Dario Amodei and Buck Shlegeris
- Summarizing Books with Human Feedback (2021) by Jeffrey Wu, Ryan Lowe and Jan Leike
- Language Models Perform Reasoning via Chain of Thought (2022) by Jason Wei, Denny Zhou and Google
- Least-to-Most Prompting Enables Complex Reasoning in Large Language Models (2022) by Denny Zhou et alia
Materials for Week 5: Adversarial techniques for scalable oversight [~90 minutes]
- AI-written critiques help humans notice flaws: blog post (2022) by Jan Leike et alia
- AI safety via debate (2018) by Geoffrey Irving, Paul Christiano and Dario Amodei
- Red-teaming language models with language models (2022) by Ethan Perez et alia
- [Advanced ML] Robust Feature-Level Adversaries are Interpretability Tools (2021) by Casper et alia
- High-stakes alignment via adversarial training blog posts (2022) by Daniel Ziegler et alia
- Takeaways from our robust injury classifier project (2022) by Daniel Ziegler et alia
- [Optional] WebGPT (2021) by Jacob Hilton et alia
- [Optional] Debate update: Obfuscated arguments problem (2020) by “Beth Barnes” and Paul Christiano
- [Optional] Training robust corrigibility (2019) by Paul Christiano
Materials for Week 6: Interpretability [~100 minutes]
- Feature Visualization (2017) by Chris Olah et alia
- Zoom In: An Introduction to Circuits (2020) by Chris Olah et alia
- [Advanced ML] Toy Models of Superposition (2022) by Nelson Elhage et alia
- Understanding intermediate layers using linear classifier probes (2016) by Guillaume Alain and Yoshua Bengio
- [Advanced ML] Discovering Latent Knowledge in Language Models Without Supervision (2022) by Collin Burns
- Acquisition of Chess Knowledge in AlphaZero (2021) by Thomas McGrath et alia
- Locating and Editing Factual Associations in GPT (2022) by Kevin Meng et alia
- [Advanced ML & Optional] Eliciting latent knowledge (2021) by Paul Christiano et alia
- [My Addition] Chris Olah Interview on the 80k Podcast
Materials for Week 7 - Default: Governance [~80 minutes]
- [Video] AI Strategy, Policy, and Governance (2019) by Allan Dafoe
- AI Governance: Opportunity and Theory of Impact (2020) by Allan Dafoe
- The AI deployment problem (2022) by Holden Karnofsky
- Why and How Governments Should Monitor AI Development (2021) by Jess Whittlestone and Jack Clarke
- Transformative AI and Compute (2021) by Lennart Heim
- Information security considerations for AI and the long term future (2022) by Jeffrey Ladish and Lennart Heim
- [Optional] Sharing Powerful AI Models (2022) by Toby Shevlane
- [Optional] AI Governance: A research agenda (2018) by Allan Dafoe
- [Optional] Some AI governance research ideas (2021) by Markus Anderljung and Alexis Carlier
- [Optional] The Semiconductor Supply Chain (2021) by Saif M. Khan
- [Optional] The Global AI talent tracker (2020) by Macro Polo
- [My Addition] Could Advanced AI Drive Explosive Economic Growth (2021) by Tom Davidson
- GPTs are GPTs by Tyna Eloundou et alia
- Sparks of AGI in GPT4 by Sebastien Bubeck et alia
Materials for Week 7 - Alternative: Agent Foundations [~100 minutes]
- What is AIXI? (2020) by Marcus Hutter
- Embedded Agents: Part 1 (2018) by Scott Garrabrant and Demski
- Logical decision theory (2017) by Eliezer Yudkowsky
- Logical Induction: Blog post (2016) by Nate Soares
- Progress on Causal Influence diagrams: blog post (2021) by Tom Everitt et alia
- Avoiding Side Effects By Considering Future Tasks (2020) by Victoria Krakovna
- Cooperation, Conflict and Transformative AI (2019) by Jesse Clifton